
T5
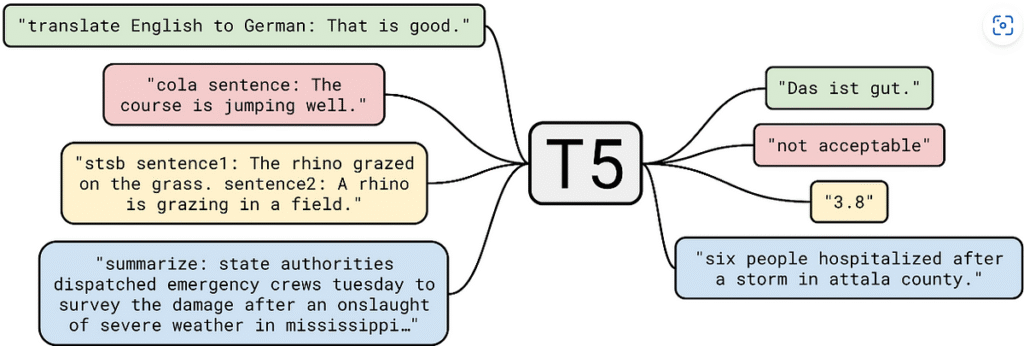
The Text-to-Text Transfer Transformer (T5) has emerged as one of the most versatile pre-trained architectures for natural language understanding and generation. At its core, each Transformer layer combines a multi-head self-attention (MHA) sublayer with a position-wise feed-forward network (FFN). The FFN is typically a two-layer MLP with a nonlinearity, expressed as:
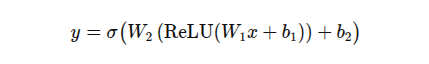
This design—shown above—provides the model with the capacity to mix and transform features independently at each sequence position before passing them onward through residual connections and layer normalization.
The Kolmogorov–Arnold Network (KAN)
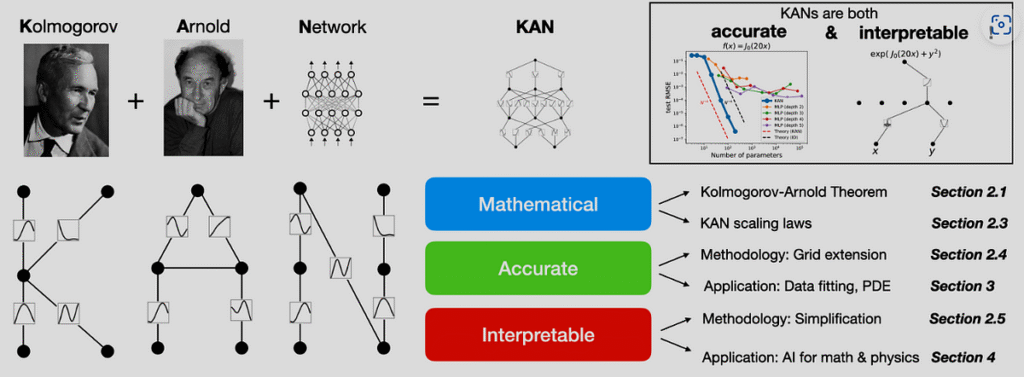
Building on the Kolmogorov–Arnold representation theorem, the Kolmogorov–Arnold Network (KAN) replaces the standard FFN with a superposition of one-dimensional spline functions. In brief:
- SplineFunction modules learn a set of knots and coefficients to approximate arbitrary continuous mappings on each input dimension.
- A bank of these input splines transforms the incoming features.
- Another bank of output splines remaps the intermediate representation back into the model’s hidden dimension.
This leverages the theorem’s guarantee that any multivariate continuous function can be decomposed into sums and compositions of univariate functions—here instantiated as trainable cubic splines.
What Motivated Me
- Expressivity vs. Simplicity: While the two-layer FFN is powerful, I wanted to explore whether a theoretically grounded function approximator could yield richer nonlinear transforms without exploding parameter counts.
- Theoretical Foundations: The Kolmogorov–Arnold theorem suggests a principled route to universal approximation. Could we bring those guarantees into a Transformer?
- Novel Architectures: Pushing the envelope of Transformer design by hybridizing classical representation theorems with modern deep learning.
The Complete Experimented Code
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torch.utils.data import DataLoader, TensorDataset
# Positional Encoding
class P_E(nn.Module):
def __init__(self, model_dimension, expected_max_sequence_length=5000):
super().__init__()
pos_en = np.array([
[pos / np.power(10000, 2 * (i // 2) / model_dimension) for i in range(model_dimension)]
if pos != 0 else np.zeros(model_dimension)
for pos in range(expected_max_sequence_length)
])
pos_en[1:, 0::2] = np.sin(pos_en[1:, 0::2])
pos_en[1:, 1::2] = np.cos(pos_en[1:, 1::2])
self.pos_en = torch.FloatTensor(pos_en)
def forward(self, embeddings):
pe = self.pos_en[:embeddings.shape[1]].to(embeddings.device)
return embeddings + pe
# Spline Function
class SplineFunction(nn.Module):
def __init__(self, input_dim, num_knots):
super(SplineFunction, self).__init__()
self.num_knots = num_knots
self.knots = nn.Parameter(torch.randn(num_knots, input_dim))
self.coefs = nn.Parameter(torch.randn(num_knots, input_dim))
def forward(self, x):
batch_size, input_dim = x.size()
x_expanded = x.unsqueeze(1).expand(-1, self.num_knots, -1)
knot_weights = torch.max(self.knots - x_expanded, torch.zeros_like(self.knots)).pow(3)
output = torch.sum(knot_weights * self.coefs, dim=1)
return output
# KA Network
class KANetwork(nn.Module):
def __init__(self, input_dim, output_dim, num_knots=10):
super(KANetwork, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.num_knots = num_knots
self.input_splines = nn.ModuleList([SplineFunction(1, num_knots) for _ in range(input_dim)])
self.output_splines = nn.ModuleList([SplineFunction(1, num_knots) for _ in range(output_dim)])
def forward(self, x):
batch_size, seq_len, _ = x.size()
x = x.view(batch_size * seq_len, self.input_dim)
x = torch.cat([spline(x[:, i:i+1]) for i, spline in enumerate(self.input_splines)], dim=1)
x = torch.cat([spline(x[:, i:i+1]) for i, spline in enumerate(self.output_splines)], dim=1)
x = x.view(batch_size, seq_len, self.output_dim)
return x
# Multi-Head Attention
class mha(nn.Module):
def __init__(self, h_dim, n_heads):
super().__init__()
self.h_dim = h_dim
self.num_heads = n_heads
self.norm = nn.LayerNorm(h_dim)
self.dropout = nn.Dropout(0.2)
self.softmax = nn.Softmax(dim=2)
def forward(self, q, k, v, masked):
rs = q.size()[0]
q2 = torch.cat(torch.chunk(q, self.num_heads, dim=2), dim=0)
k2 = torch.cat(torch.chunk(k, self.num_heads, dim=2), dim=0)
v2 = torch.cat(torch.chunk(v, self.num_heads, dim=2), dim=0)
outputs = torch.bmm(q2, k2.transpose(2, 1)) / (k2.size()[-1] ** 0.5)
if masked:
k_masks = torch.sign(torch.abs(k).sum(dim=-1)).repeat(self.num_heads, 1)
k_masks = k_masks.unsqueeze(1).repeat(1, q.size()[1], 1)
paddings = torch.ones_like(k_masks) * (-2 ** 32 + 1)
outputs = torch.where(k_masks == 0, paddings, outputs)
outputs = self.softmax(outputs)
q_masks = torch.sign(torch.abs(q).sum(dim=-1)).repeat(self.num_heads, 1)
q_masks = q_masks.unsqueeze(-1).repeat(1, 1, k.size()[1])
outputs = outputs * q_masks
else:
outputs = self.softmax(outputs)
outputs = self.dropout(outputs)
outputs = torch.bmm(outputs, v2)
outputs = torch.cat(torch.split(outputs, rs, dim=0), dim=2)
outputs = outputs + q
return self.norm(outputs)
# Encoder-Decoder Block
class EncoderDecoder(nn.Module):
def __init__(self, model_dimension, n_heads):
super().__init__()
self.mha = mha(model_dimension, n_heads)
self.ka_network = KANetwork(model_dimension, model_dimension)
def forward(self, embeddings_wp, enc=None, x_mask=None, y_mask=None):
# Self-attention (and cross-attention if enc is provided)
multi_head_attention = self.mha(embeddings_wp, embeddings_wp, embeddings_wp, x_mask)
if enc is not None:
multi_head_attention = self.mha(multi_head_attention, enc, enc, y_mask)
# KA-based nonlinear transform in place of FFN
ka_output = self.ka_network(multi_head_attention)
return ka_output
# Full Transformer
class Transformer(nn.Module):
def __init__(self, inp_vocab, model_dimension, n_heads, _num_layers):
super().__init__()
self.emb = nn.Embedding(inp_vocab, model_dimension)
self.Pos_Embedding = P_E(model_dimension)
self.dropout = nn.Dropout(p=0.2)
# Shared EncoderDecoder block for stacking
self._layers = nn.ModuleList([
EncoderDecoder(model_dimension, n_heads) for _ in range(_num_layers)
])
self.linear = nn.Linear(model_dimension, inp_vocab)
self.log_softmax = nn.LogSoftmax(dim=-1)
def forward(self, x, y, x_mask, y_mask):
# Encoder
embeddings = self.emb(x)
pos_embeddings = self.Pos_Embedding(embeddings)
enc_state = self.dropout(embeddings + pos_embeddings)
for layer in self._layers:
enc_state = layer(enc_state, None, x_mask, None)
# Decoder
embeddings2 = self.emb(y)
pos_embeddings2 = self.Pos_Embedding(embeddings2)
dec_state = self.dropout(embeddings2 + pos_embeddings2)
for layer in self._layers:
dec_state = layer(dec_state, enc_state, x_mask, y_mask)
# Final projection
lin = self.linear(dec_state)
return self.log_softmax(lin)
# Data setup
X_train = torch.randint(1, 21, (100, 20))
Y_train = torch.randint(1, 21, (100, 20))
dataset = TensorDataset(X_train, Y_train)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
# Initialize, train
model = Transformer(inp_vocab=21, model_dimension=128, n_heads=8, _num_layers=2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
for epoch in range(5):
total_loss = 0
for X_batch, Y_batch in dataloader:
optimizer.zero_grad()
output = model(X_batch, Y_batch, x_mask=None, y_mask=None)
loss = criterion(output.view(-1, 21), Y_batch.view(-1))
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {total_loss / len(dataloader)}')
What Changed
In KAT5, we replace the standard two-layer FFN
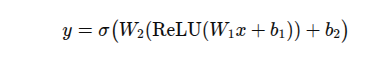
with a Kolmogorov–Arnold–inspired spline superposition:
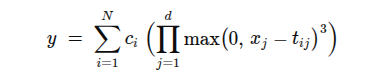
Key differences:

As a result, the end-to-end conditional probability of token sequences in KAT5 becomes:
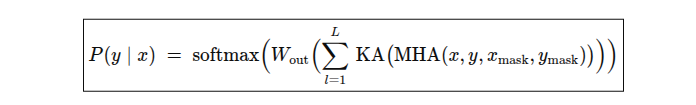
- MHA produces contextualized embeddings via multi-head self- and cross-attention.
- KA applies the spline-based transform in place of the traditional FFN.
- Summing over all L layers aggregates deep, nonlinear representations.
- A final linear projection W (out) and softmax yield token probabilities.
This new formulation marries the rich expressivity of KAN with the powerful sequence modeling of Transformers, grounded in both empirical practice and classical approximation theory.
How It Benefited
- Richer Nonlinear Transforms: Spline-based mapping captures subtle, high-order interactions that a single ReLU may miss.
- Parameter Efficiency: For moderate n(knots), KAN can approximate complex functions with fewer degrees of freedom than a very wide FFN.
- Theoretical Guarantees: Grounding in the Kolmogorov–Arnold theorem provides confidence in universal approximation given sufficient knots.
- Modularity: KAN blocks plug directly into any Transformer implementation, facilitating easy experimentation.
Challenges
- Training Stability: Spline coefficients and knot locations may exhibit unstable gradients early in training, requiring careful initialization and gradient clipping.
- Computational Overhead: Evaluating multiple cubic spline kernels per token increases both memory and compute per forward pass.
- Hyperparameter Tuning: Choosing the number of knots (n knots) and learning rates for spline parameters demands extensive grid search.
Limitations
- Scalability: As sequence length or model dimension grows, the overhead of O(n knots×d) spline evaluations can become prohibitive.
- Generalization: While expressive, splines may overfit small datasets if regularization is insufficient.
- Integration: Off-the-shelf Transformer libraries may require nontrivial adjustments to swap in KAN blocks.
Future Work
- Adaptive Knots: Learn not only coefficients but also the knot positions dynamically during training.
- Compression: Explore low-rank or shared-knot strategies to reduce the overhead of separate splines per feature.
- Hybrid Architectures: Combine KAN with lightweight MLPs or gating mechanisms to balance expressivity and efficiency.
- Benchmarking: Systematic evaluation on large-scale translation, summarization, and language modeling tasks to quantify gains.
References
- Raffel, C. et al. (2020). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (T5).
- Kolmogorov, A. N. (1957). On the representation of continuous functions of many variables by superpositions of continuous functions of a smaller number of variables.
- Arnold, V. I. (1957). On functions of three variables.
- Goodfellow, I. et al. (2016). Deep Learning. MIT Press.
- Vaswani, A. et al. (2017). Attention Is All You Need.
This experimental initiative demonstrates how classical mathematical theorems can inspire novel neural architectures that push beyond standard Transformer designs.


