Three months ago, I grew tired of embedding-based search systems. They seemed interesting at first, but they struggled with nuanced queries. Searching for “chest pain in elderly patients with diabetes” brought up generic cardiovascular content, missing crucial connections. It was time for a smarter solution. Then I discovered ELITE: Embedding-Less retrieval with Iterative Text Exploration, a breakthrough from 2025 that not only improves RAG but truly redefines it.
What’s New & Cutting-Edge in ELITE?
1. Rock-Solid Efficiency
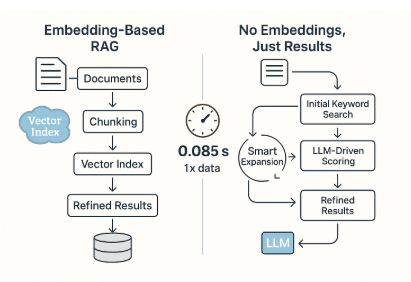
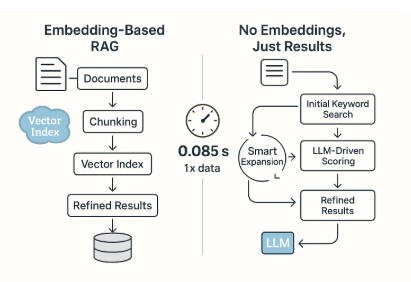
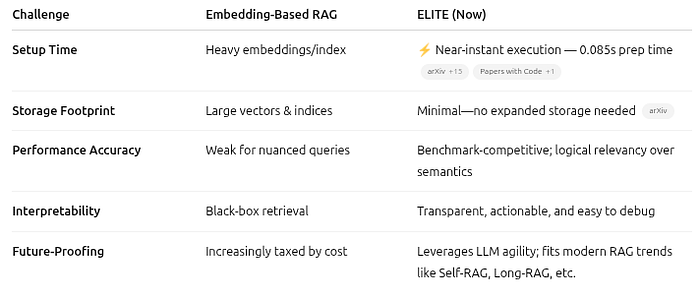
ELITE completely removes embedding models and dense indexes. It relies on LLM-guided logic. In tests, it reduced preparatory runtime from 19,337 seconds to just 0.085 seconds, which dramatically decreased total runtime.
2. Benchmark-Ready Performance
Using LLaMA 3.1‑70B:
— NovelQA: 71.27% (2nd place behind GPT‑4‑0125‑preview at 71.80%)
— Marathon: 68.46% (2nd to GPT‑4 at 78.59%)
3. Reasoning, Not Approximation
ELITE uses the reasoning power of LLMs to refine searches iteratively, tracking logically related content rather than just semantically similar vectors. This approach offers transparency, flexibility, and precise scaling.
4. EMERGING RAG TRENDS
Embedding-free methods are gaining popularity. As of August 2025, platforms like DigitalOcean are highlighting alternatives, including ELITE, to address the limits of embedding systems and their performance costs.
Complementary innovations are also increasing:
- Self-RAG: Adds self-reflection and dynamic retrieval decision-making.
- Long RAG: Efficiently handles longer text units to reduce chunk fragmentation.
- TreeHop / QuOTE: Embed-free multi-hop reasoning or strategies enriched with question semantics.
- HippoRAG 2: Incorporates human-like continual learning into RAG systems.
ELITE in Action
How It Works:
- Initial Keyword Search: A simple, fast match kicks off the retrieval process.
- LLM-Guided Scoring: An LLM assesses relevance with an “importance” measure.
- Iterative Expansion: The search dynamically extends based on top candidates.
- Transparent Reasoning: It combines human and algorithmic methods, making it easy to debug and understand.
Python Prototype
import openai
from typing import List
openai.api_key = "YOUR_API_KEY"
def score_importance(ctx: str, q: str) -> float:
resp = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Rate relevance (0–1):"},
{"role": "user", "content": f"Context:\n{ctx}\n\nQuery:\n{q}"}
],
temperature=0.0
)
return float(resp.choices[0].message.content.strip())
def elite_retrieve(docs: List[str], query: str, rounds=3, top_k=2):
candidates = docs
for _ in range(rounds):
scored = [(doc, score_importance(doc, query)) for doc in candidates]
scored.sort(key=lambda x: x[1], reverse=True)
candidates = [doc for doc, _ in scored[:top_k]]
return candidates
def generate_answer(contexts: List[str], query: str) -> str:
prompt = f"{query}\n\nContexts:\n" + "\n - -\n".join(contexts)
resp = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return resp.choices[0].message.content.strip()Why ELITE Matters to AI/ML Practitioners
What’s Next for ELITE?
- Multi-Lingual & Domain-Specific Customization: For fields like healthcare, law, and finance, ELITE’s reasoning-first design supports tailored adaptations.
- Real-Time Learning Enhancements: Integrate online feedback loops to improve importance scoring based on current usage.
- Hybrid Methods: Implement lightweight BM25 or Long-RAG filtering before ELITE rounds to cut down on LLM calls while keeping relevance.
- Agentic RAG Integration: Apply ELITE’s core logic within multi-agent systems for immediate tool use and memory enhancement.
Final Thought
In a world focused on larger models and complex embedding processes, ELITE shows us that simplicity, logic, and iteration lead to better performance. It is fast, transparent, and top-quality without unnecessary overhead.


